At any conference, you start to feel fatigued near the end of the day. Between the sprawling session locations, the constant engagement, and the sometimes overwhelming number of people and places to navigate, attention begins to wan by the last sessions you attend. Presenters in the unfortunate end-of-day time slots are between attendees and dinner. I was pleasantly surprised to be reinvigorated after attending my second to last session of the day. Presenters Connie Yu and Joana Cruz, of Target, managed to bring humor, excitement, and energy to their topic, titled: Achieve Enterprise Agility at Edge Locations by adopting Kubernetes, Spinnaker and Unimatrix.
My background is in software defined infrastructure orchestration at scale, both in a data center environment, as well as in my company’s private cloud deployment. I was curious to see this type of orchestration in use by a retailer to manage their in store deployments. Connie and Joana structured their session as a humorous conversation on how the stores could adopt supply chain methodologies to improve operations. By doing so, Target went from delivering software to 1850 stores just 3 times a year to multiple times daily. How? Let’s dive in!
Target’s Strategy:
Have you ever installed an operating system and all of the software you want to use on it from scratch? Most consumers buy an off the shelf system that has already been configured for their baseline needs. In an enterprise environment, IT is (usually) responsible for installing and configuring the “stack” — the operating system and all necessary software, in addition to modifying settings to secure and optimize the system, and they have to do this for thousands of systems, not just one. If you had to hand build thousands of systems, given your experience having done it just for one, then you know, it can be tedious, and error-prone work. The time spent to automate the process is well worth the investment as it saves countless hours and makes deployment repeatable, predictable, and scalable. To do this, you need the right tools, and you also need to take the time to consider the architecture to ensure it will meet the requirements.
There are unique infrastructure constraints in a retail store setting. The primary compute resources are thin clients, which have less I/O, Memory, Storage and CPU than you would find in a traditional data center. For this reason, some of the conventional architectures, like server:client segmentation, have to be redesigned to run at the edge. Target presented three primary components of their edge computing solution.

Microservices are lightweight and loosely coupled which makes the architecture a good fit for distributed computing with limited resources, as is the case in the edge retail environment. Containers allow application dependencies, packages, and software to be fully encapsulated so that they run in an isolated environment side by side with other containers — a logical choice for consolidating services on your infrastructure without disturbing functionality. With microservices, they are typically implemented using REST which often leverages HTTP, and securing all of the data flowing between the services on different endpoints is crucial to maintaining security — no store wants to become the next data breach cautionary tale.
Orchestration
Orchestration, in brief, is the practice of automating the configuration and management of your infrastructure. Whether you have three systems or thousands, managing them is far easier when you have the right tools. Target chose the open source orchestration platform Kubernetes, as their orchestration agent.
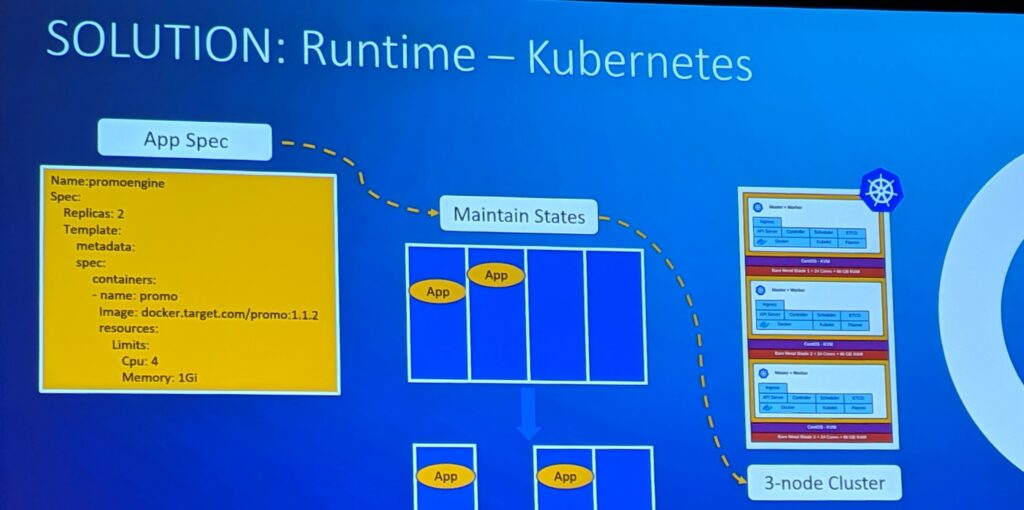
The primary reasons cited for this choice were: self healing, state maintenance, and high availability. Often, the task of running and scheduling of workloads is segmented onto two different servers. In this case, Target containerized the applications and co-located them on the same host and had a cluster of servers that provided the functionality, thereby achieving consolidation and redundancy.
Deployment
The deployment tool of choice for Target was Spinnaker. I had never heard of it before. If you’re like me you had to Google it. I’ll save you the trouble, here is the Cliff’s Notes version: It is an open source tool that supports multiple cloud providers and integrates with many existing orchestration tools (like Kubernetes).
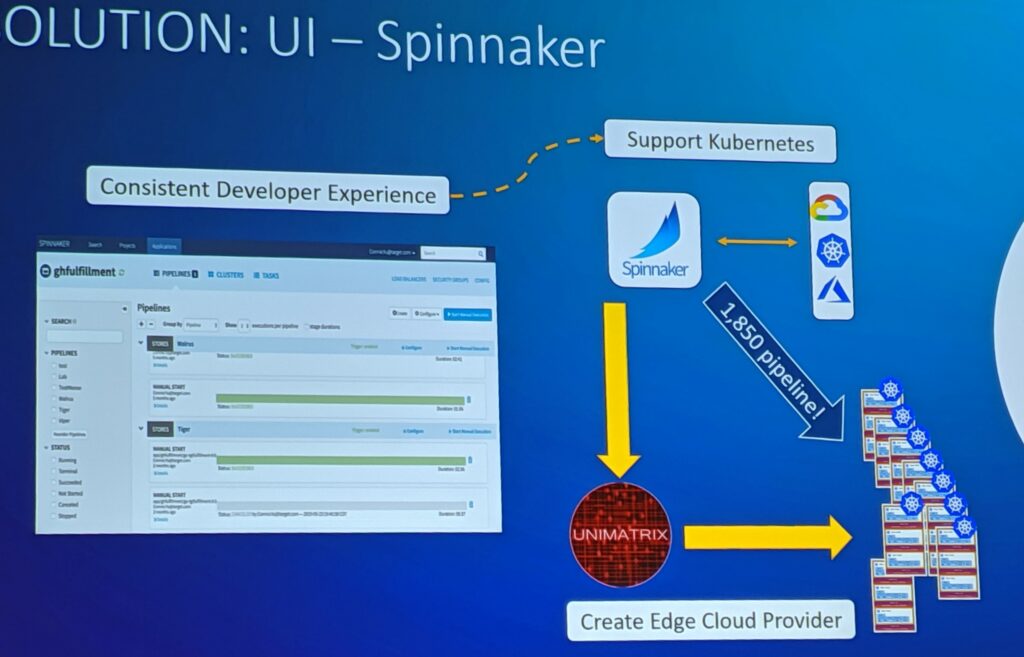
Spinnaker uses the concepts of applications, clusters, and server groups to construct and manage deployment piplines. In short, it allows you to automate which target devices you want to install your software on.
Edge Cloud
One of the points Connie and Joana mentioned was that Target had few corproate datacenters, but 1,855 stores all with their own infrastructure. They wanted to manage each store like its own cloud, and so they needed an edge cloud provider.
Target named their edge cloud provider Unimatrix, which is a nod to Star Trek. Unimatrix commands and controls all of the Kubernetes deployments at the edge.
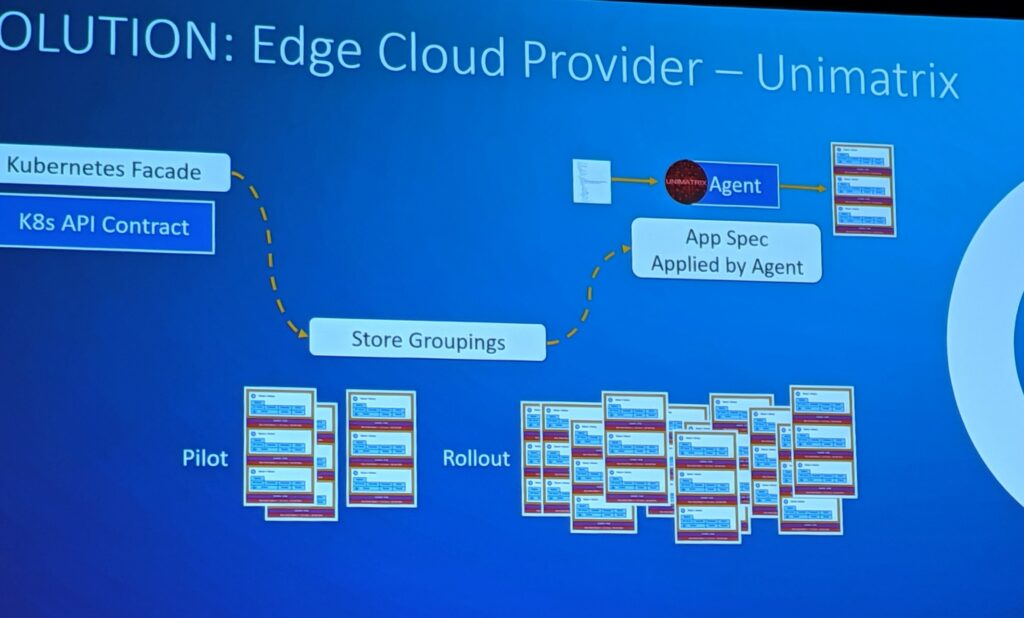
Unimatrix reuses the existing Kubernetes API, and allows deployment by pilot, mass roll out, or even by store regions. Maintaining the API contract and only adding additional microservices to augment custom requirements allowed Target to continue using the existing Spinnaker and Kubernetes integration. An additional component is the Unimatrix agent. The agent takes the role of the operator. It applies the application spec to the Kubernetes clusters. As the spec is applied, it reports back to Unimatrix, which syncs the state to Spinnaker so the developer can see the deployment progress. You can read more in depth about Unimatrix on the Target blog.
Demoing the Use case: Deploy a promotion
Now that we know all of the components of the system, we can see the process in action.
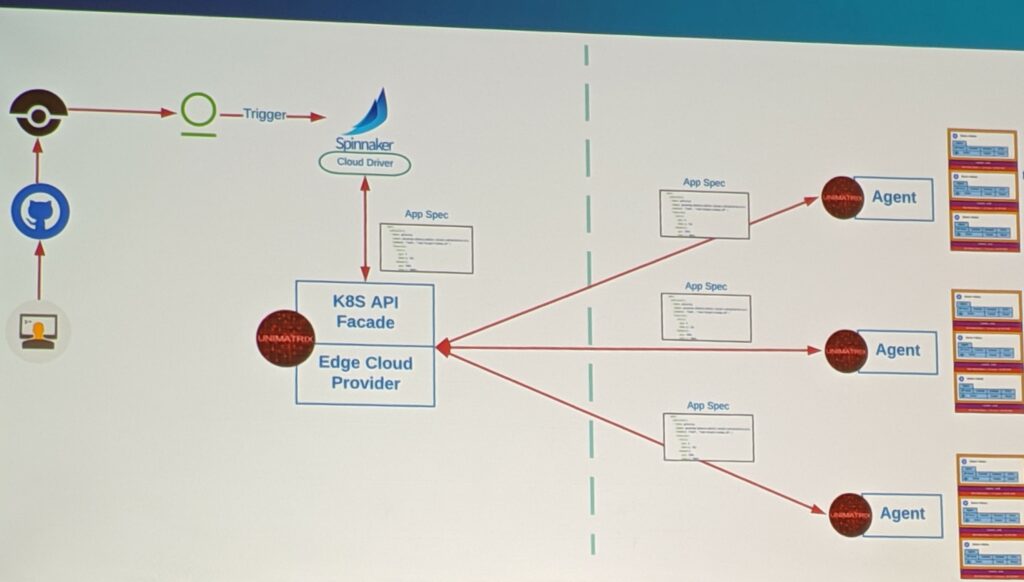
- All promotion change features implemented as microservices
- Push code to Git
- Security tools triggered to ensure
- Build process ensues
- Code goes into docker registry
- The Spinnaker pipeline is triggered, and pushes the application spec to the Unimatrix central server
- The Unimatrix deployment server begins to sync application spec to the agents in the defined pipelines
As all of this is happening, the state of the deployment is maintained and can be visualized in Spinnaker:
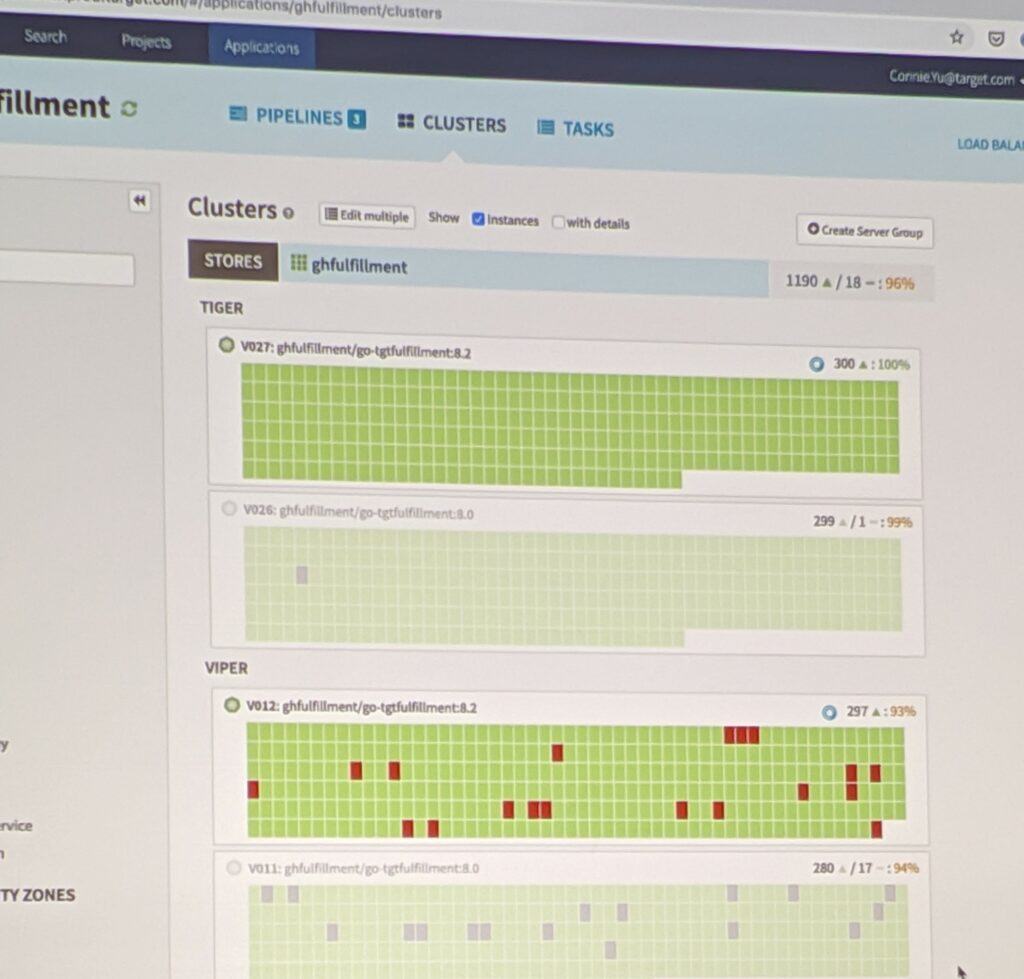
And that is how it’s done!
Success
So their teams did all of that work. What was the result?
- On boarded > 90 applications in the first 6 months; which included IoT platforms, new microservices, and video machine learning capabilities.
- Running in production at Target edge locations
How did they accomplish this success? The answer — defining very clear objectives from day one:
- The ability to deploy to stores in a targeted fashion (pun intended)
- Enable application developers to do the deployments
- Have clear measurements of progress
- Reusing tools allowed developers to rapidly adopt the technology
- Flexibility during the solution building — Target accelerated development by using open source, and created custom solutions only when necessary
Not to be biased, but…this was my FAVORITE GHC session. I loved the humorous exchanges between Joana and Connie, they were well rehearsed, knew the material, the flow was logically presented and really took the audience on the journey of WHY developing this technology was necessary, how they implemented the solution, and the return on the investment. Also, might I add, the speakers had the best red tennis shoes, very on brand.